")
Reducing AI’s Climate Impact: Everything You Always Wanted to Know but Were Afraid to Ask

An Inconvenient Truth: Smoke Signals
Your cell phone has smokestack emissions. So too does your electric vehicle. The simple reason for this is that, here in the US, only 3.6% of energy supply in 2023 came from renewable sources such as wind, solar, hydroelectric and geothermal. Fossil fuels remain our predominant way of generating electricity.
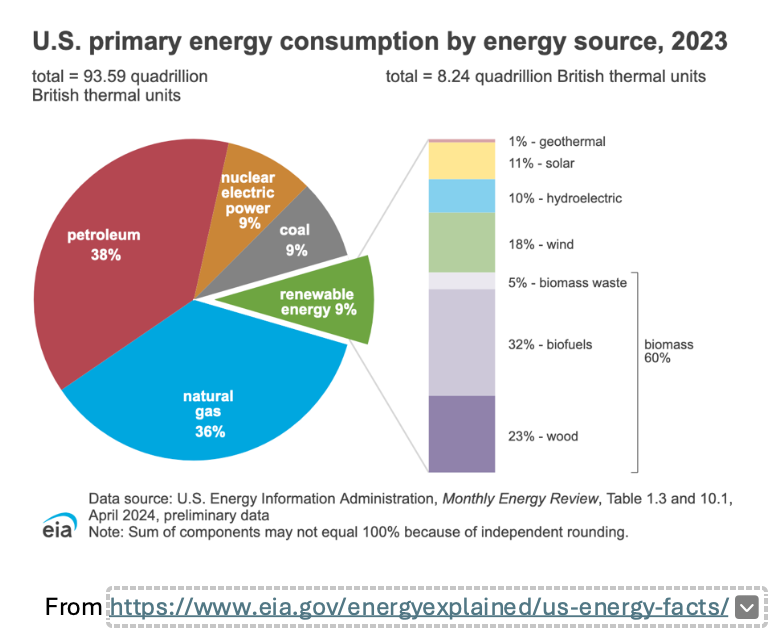
The picture is equally bleak on a worldwide basis, with fossil fuels meeting the bulk of our energy demands, turning every electrically powered device, from cell phone, to electric vehicle, to data center server, into an exhaust-spewing challenge to Mother Nature.
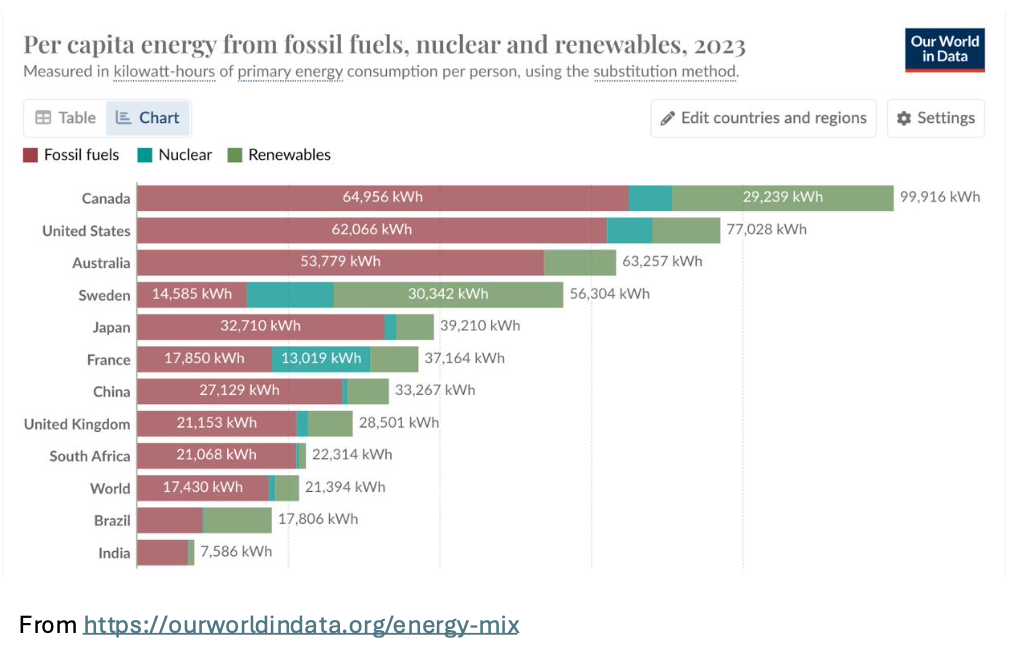
In our increasingly digitized world, the needs from computation, and artificial intelligence in particular, are now creating a profound new climate stress. As the use of AI spreads into all aspects of human life and business, it extends ever more its demands for power and water.
Just how much power and water are we talking about? AI-driven data center power consumption is slated to soon reach 8.4 TWh (Chien 2023) which “is 3.25 gigatons of CO2, the equivalent of 5 billion U.S. cross-country flights”. Yale’s School of the Environment found that “Data centers’ electricity consumption in 2026 is projected to reach 1,000 terawatts, roughly Japan’s total consumption” (Berreby 2024), while researchers at UC Riverside found that the global AI demand for water in 2027 would be 4.2-6.6 billion cubic meters, roughly equivalent to the consumption of “half of the United Kingdom” (Li et al. 2023). Ouch.
To address the accelerating demands of AI’s energy consumption, the ideal solution would be to transition to 100% renewable energy, but this goal is currently distant. A more feasible approach is the syncretic one, combining specialized AI hardware and software, innovative data center designs, and the implementation of comprehensive AI policies, including regulation. This discussion will outline current strategies for reducing AI’s energy demands, with many solutions derived from software technology, thus enhancing their accessibility to AI practitioners.
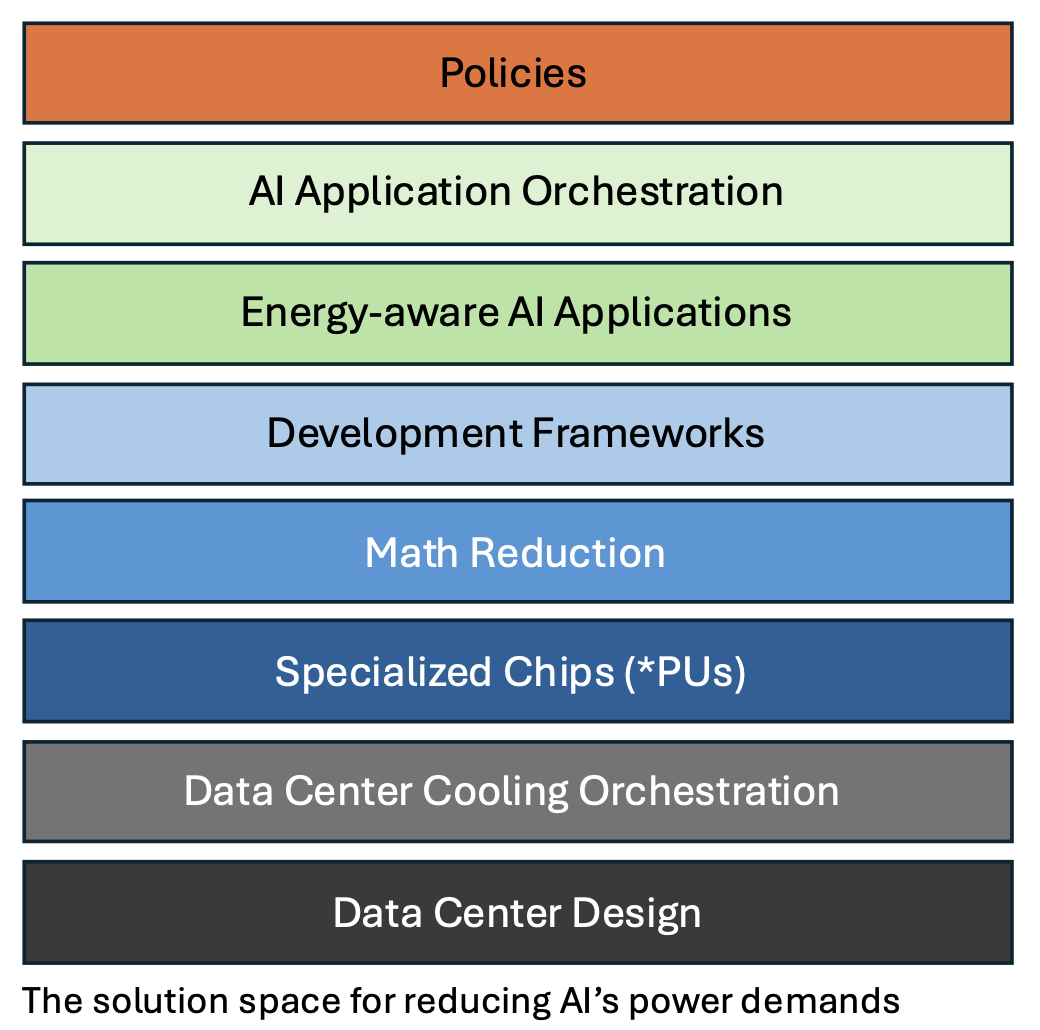
Data Center Design
To address the heat generated by AI computations in data centers, which necessitates significant cooling energy, multiple different cooling methods can be employed. Free air cooling, which uses outdoor air to cool indoor environments, is highly efficient and uses minimal water but only works in cooler climates. Evaporative (adiabatic) cooling also provides efficient cooling with low power and water usage. Some recent designs utilize submersion cooling, where hardware is immersed in a dielectric fluid that transfers heat without conducting electricity, thus eliminating the need for traditional air conditioning. Conversely, mechanical air conditioning is least effective due to high power and water costs.
While nuclear power via small modular reactors (SMRs) is sometimes proposed as a cleaner energy solution for data centers, their deployment will take years, and they face similar safety, waste, and economic concerns as larger reactors. Instead, focusing on renewable energy sources and storage solutions, such as solar power, may offer more immediate benefits for meeting data center energy needs.
Specialized Chips

Since the mid-19th century, internal combustion engines have evolved into highly specialized devices for various applications, from lawnmowers to jumbo jets. Today, AI hardware is undergoing a similar evolution, with specialized, high-performance processors replacing less efficient general-purpose CPUs. Google’s introduction of the tensor processing unit (TPU) in 2015 marked a bellwether advance in custom-designed AI hardware. NVIDIA’s GPUs, which excel in parallel processing for deep learning and large-scale data operations, have driven substantial growth in both sales and stock valuation. As AI demand increases, we can anticipate a proliferation of vendors offering increasingly specialized processors that deliver superior computation speeds at lower energy costs.
Recent examples of this inevitable wave include Groq, a company building a language processing unit (LPU). Groq claims its custom hardware runs generative AI models similar to those from OpenAI “at 10x the speed and one-tenth the energy”. Also included in the list is Cerebras Systems’ wafer-scale chip, which “runs 20 times faster than NVIDIA GPUs”. Then there’s Etched’s Sohu ASIC, which burns the transformer architecture directly into the silicon, so “can run AI models an order of magnitude faster and cheaper than GPUs”; SiMa.ai which claims “10x performance”; and of course Amazon’s Trainium, Graviton and Inferentia processors.
The future of chip innovation may lie in biomimetic design, inspired by nature’s energy-efficient intelligence. Technologies like those developed by FinalSpark are expected to contribute to this trend. However, access to specialized processors is likely to remain a competitive landscape, with smaller companies facing particular challenges.
Orchestrating the Cooling Plant
Data center cooling equipment includes chillers, pumps and cooling towers. Can this equipment be run in an optimal fashion in order to maximize cooling while minimizing energy? In 2016, engineers at Google did just that, implementing a neural network (Evans & Gao 2016) featuring five hidden layers with 50 nodes per layer, and 19 discrete input variables, including data from the cooling equipment and weather conditions outdoors. Trained on 2 years’ worth of operating data, this neural network succeeded in reducing the energy used for cooling Google’s data centers by a whopping 40%. (Despite this, Google’s greenhouse gas emissions have skyrocketed 48% in the past 5 years thanks to the relentless demands of AI.)
Orchestrating AI Training & Inference
In addition to using software to orchestrate the cooling machinery in a data center, the same can be done with the AI applications running there. By optimizing what gets run (if at all), where it’s run and when it’s run, data centers can achieve substantial energy savings on their AI workloads. (As a simple example, imagine moving an AI workload from the afternoon to the early morning hours and saving 10% of the energy right off the bat.).

Orchestration of AI falls into two categories: orchestrating the AI training process, and orchestrating AI at inference (runtime). There are a number of different approaches being taken in the orchestration of AI training. Two promising tacks are power-capping (McDonald et al. 2022) and training performance estimation (TPE; Frey et al. 2022). In the former, standard NVIDIA utilities were used to cap the power budget available for training a BERT language model. Though the power cap led to a longer time-to-train, the resulting energy savings were material, with “a 150W bound on power utilization [leading] to an average 13.7% decrease in energy usage and 6.8% increase in training time.”
TPE is based on the principle of early stopping during AI training. Instead of training every model and hyperparameter configuration to full convergence over 100 epochs, which incurs significant energy costs, networks might be trained for only 10-20 epochs. At this stage, a snapshot is taken to compare performance with other models, allowing for the elimination of non-optimal configurations and retention of the most promising ones. “By predicting the final, converged model performance from only a few initial epochs of training, early stopping [of slow-converging models] saves energy without a significant drop in performance.” The authors note that “In this way, 80-90% energy savings are achieved simply by performing HPO [hyperparameter optimization] without training to convergence.”
Approximately 80% of AI’s workload involves inference, making its optimization crucial for energy reduction. An illustrative example is CLOVER (Li et al., 2023), which achieves energy savings through two key optimizations: GPU resource partitioning and mixed-quality models. GPU partitioning enhances efficiency by orchestrating resource utilization at the GPU level. Mixed-quality models refers to the availability of multiple models with different qualities in accuracy and resource needs. “Creating a mixture of model variants (i.e., a mixture of low- and high-quality models) provides an opportunity for significant reduction in the carbon footprint” by allowing the best model variant to be orchestrated at runtime, trading off accuracy against carbon savings. CLOVER’s mixed-quality inference services combined with GPU partitioning has proven highly effective, yielding “over 75% carbon emission savings across all applications with minimal accuracy degradation (2-4%)”.
Orchestration from a portfolio of mixed-quality models brings tremendous promise. Imagine intelligently trading off energy versus accuracy at runtime based on real-time requirements. As a further example, it’s been shown that “the answers generated by [the smaller] GPT-Neo 1.3B have similar quality of answers generated by [the larger] GPT-J 6B but GPT-Neo 1.3B only consumes 27% of the energy” and 20% as much disk (Everman et al. 2023). Yet another impactful approach to orchestration by cascading mixed-quality LLMs was shown in FrugalGPT (Chen et al. 2023). A key technique in FrugalGPT was to use a cascaded architecture to avoid querying high-resource-demand GPT-4 as long as lower-resource-demand GPT-J or J1-L were able to produce high-quality answers. “FrugalGPT can match the performance of the best individual LLM (e.g. GPT-4) with up to 98% cost reduction or improve the accuracy over GPT-4 by 4% with the same cost”.
Also notable in orchestrating machine learning inference is Kairos (Li et al. 2023). Kairos is a runtime framework that enhances machine learning inference by optimizing query throughput within quality and cost constraints. It achieves this by pooling diverse compute resources and dynamically allocating queries across that fabric for maximum efficiency. By leveraging similarities in top configurations, Kairos selects the most effective one without online evaluation. This approach can double the throughput of homogeneous solutions and outperform state-of-the-art methods by up to 70%.
From an innovation standpoint, a market opportunity exists for providing optimized AI orchestration to the data center. Evidence of the importance of AI orchestration may be seen in NVIDIA’s recent acquisition of Run:ai, a supplier of workload management and orchestration software.
Math: Less is More?
Reducing the complexity of mathematical operations is a key strategy for decreasing AI’s computational load and energy consumption. AI typically relies on 32-bit precision numbers within multi-dimensional matrices and dense neural networks. Transformer-based models like ChatGPT also use tokens in their processing. By minimizing the size and complexity of numbers, matrices, networks and tokens, significant computational savings can be achieved with minimal loss of accuracy.
Quantization, the process of reducing numerical precision, is central to this approach. It involves representing neural network parameters with lower-precision data types, such as 8-bit integers instead of 32-bit floating point numbers. This reduces memory usage and computational costs, particularly for operations like matrix multiplications (MatMul). Quantization can be applied in two ways: post-training quantization (PTQ), which rounds existing networks to lower precision, and quantization-aware training (QAT), which trains networks directly using low-precision numbers.
Recent work with OneBit (Xu et al. 2024), BitNet (QAT: Wang et al. 2023) and BiLLM (PTQ: Huang et al. 2024) have shown the efficacy – delivering accuracy while reducing memory and energy footprint – of reduced bit-width approaches. BiLLM, for example, approximated most numbers with a single bit, but utilized 2 bits for salient weights (hence average bit-widths > 1). With overall bit-widths of around 1.1, BiLLM was able to deliver consistently low perplexity scores despite its lower memory and energy costs.
Reinforcing the potential for 1-bit LLM variants is BitNet b1.58 (Ma et al. 2024), “where every parameter is ternary, taking on values of {-1, 0, 1}.” The additional value of 0 was injected into the original 1-bit BitNet, resulting in 1.58 bits in the binary system. BitNet b1.58 “requires almost no multiplication operations for matrix multiplication and can be highly optimized. Additionally, it has the same energy consumption as the original 1-bit BitNet and is much more efficient in terms of memory consumption, throughput and latency compared to FP16 LLM baselines”. BitNet b1.58 was found to “match full precision LLaMA LLM at 3B model size in terms of perplexity, while being 2.71 times faster and using 3.55 times less GPU memory. In particular, BitNet b1.58 with a 3.9B model size is 2.4 times faster, consumes 3.32 times less memory, but performs significantly better than LLaMA LLM 3B.”
Ternary neural networks (Alemdar et al. 2017) that constrain weights and activations to {−1, 0, 1} have proven to be very efficient (Liu et al. 2023, Zhu et al. 2024) because of their reduced use of memory and ability to eliminate expensive MatMul operations altogether, requiring simple addition and subtraction only. Low-bit LLMs further lend themselves to implementation in (high-performance) hardware, with native representation of each parameter as -1, 0, or 1, and simple addition or subtraction of values to avoid multiplication. Indeed, the Zhu work achieved “brain-like efficiency”, processing billion-parameter scale models at 13W of energy (lightbulb-level!), all via a custom FPGA built to exploit the lightweight mathematical operations.
Low-Rank Adaptation (LoRA; Hu et al. 2021) is a technique designed to fine-tune large pre-trained models efficiently by focusing on a low-rank (lower-dimensionality) approximation of the model’s weight matrices. Instead of updating all the model parameters, LoRA introduces additional low-rank matrices that capture essential adaptations while keeping the original weights mostly unchanged. This approach reduces computational costs and storage requirements, making it feasible to adapt large models to specific tasks with limited resources. “LoRA can reduce the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times.” In addition, LORA provides better model quality “despite having fewer trainable parameters, a higher training throughput, and, unlike adapters, no additional inference latency”.
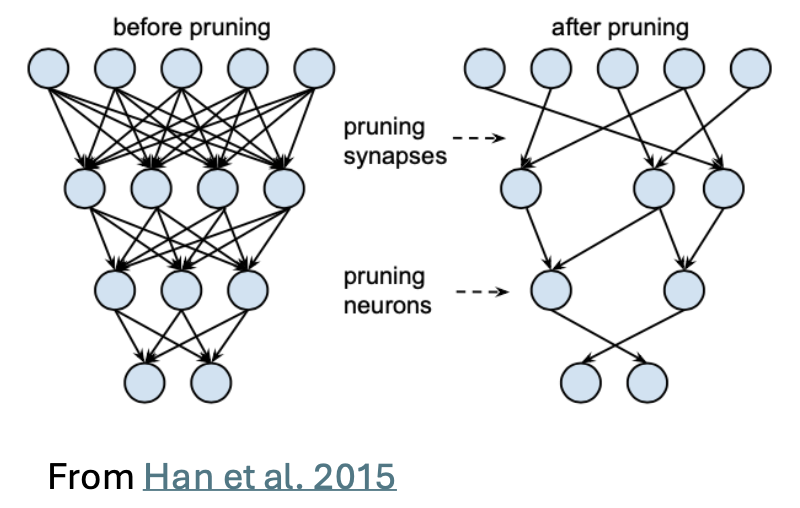
Neural network pruning achieves computational efficiency via the technique of reducing the size of a trained neural network by removing unnecessary connections (weights) or even entire neurons, thus making the network smaller, faster, and more efficient without significantly sacrificing performance. The concept was first introduced in the paper “Optimal Brain Damage” (Le Cun et al. 1989), and has been much advanced (Han et al. 2015) in the recent past. The efficiencies reported in Han et al.’s work were substantial: “On the ImageNet dataset, our method reduced the number of parameters of AlexNet by a factor of 9×, from 61 million to 6.7 million, without incurring accuracy loss. Similar experiments with VGG-16 found that the total number of parameters can be reduced by 13×, from 138 million to 10.3 million, again with no loss of accuracy.”
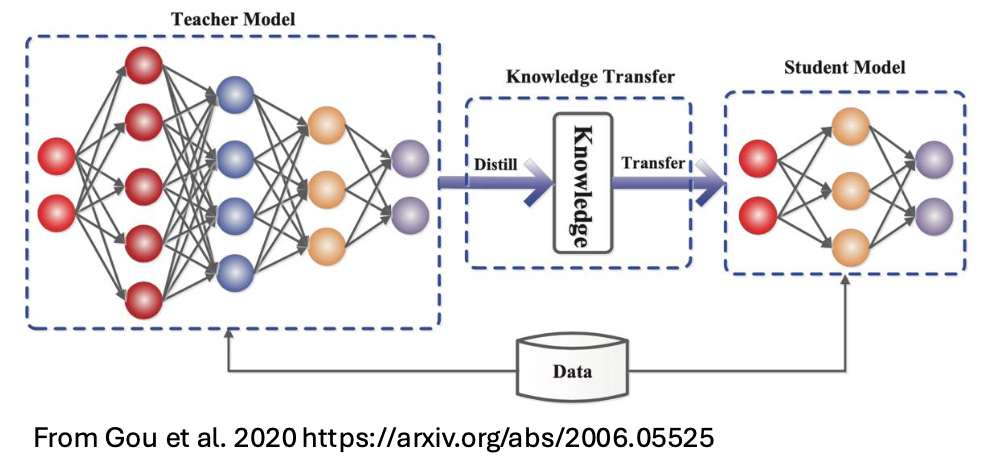
Knowledge distillation is a technique for reducing neural network size by transferring generalized knowledge from a larger “teacher” model to a smaller “student” model, perhaps similar to the Hoskins Effect in virology. This process involves distilling the teacher model’s probability distributions into the student model, which results in a more compact network that maintains high performance at lower resource costs. Knowledge distillation has proven effective in tasks such as image identification (Beyer et al., 2021), pedestrian detection (Xu et al., 2024), and small language models. For instance, NVIDIA and Mistral AI’s Mistral-NeMo-Minitron 8B achieved superior accuracy compared to other models by combining neural network pruning and knowledge distillation, despite using orders of magnitude fewer tokens.
Small language models (SLMs) also offer a method to reduce computational load and energy consumption. While SLMs are often discussed in the context of on-device applications, such as those from Microsoft and Apple, they also decrease computational and energy demands in data center environments. SLMs are characterized by smaller datasets, fewer parameters, and simpler architectures. These models are designed for low-resource settings, requiring less energy for both inference and training. Research (Schick & Schütze 2020) indicates that SLMs can achieve performance comparable to GPT-3 while having orders of magnitude fewer parameters.
Another notable optimization approach is SPROUT (Li et al., 2024), which reduces transformer math and carbon impact by decreasing the number of tokens used in language generation. SPROUT’s key insight is that the carbon footprint of LLM inference depends on both model size and token count. It employs a “generation directives” (similar to compiler directives) mechanism to adjust autoregressive inference iterations, achieving over 40% carbon savings without compromising output quality.
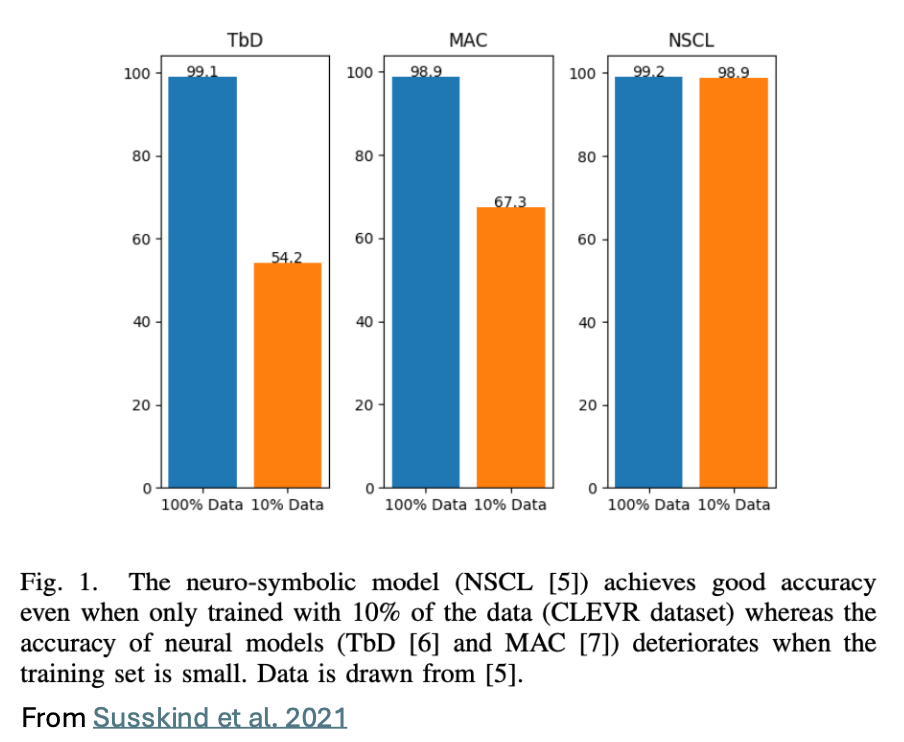
One last method for reducing AI’s computational load that brings promise is neuro-symbolic AI (NSAI; Susskind et al. 2021). NSAI integrates neural networks with symbolic reasoning, combining the strengths of both: neural networks excel at pattern recognition from large data sets, while symbolic reasoning facilitates logic-based inference. This integration aims to overcome the energy demands of neural networks and the rigidity of symbolic systems, creating more robust and adaptable AI. Research indicates that NSAI can achieve high accuracy with as little as 10% of the training data, potentially representing a pathway to sustainable AI.
Edge Computing
It should be noted that pushing AI computation to the edge, e.g., onto your mobile device, does have the effect of reducing the 40% of data center energy that’s currently spent on cooling. Energy and carbon impacts are however still incurred from charging your mobile device.
Development Frameworks
The battle for AI chip supremacy is being fought equally on the silicon as well as on the software framework that’s built atop the silicon. These frameworks increasingly provide native support for the sorts of math optimizations that have been described in this article. Pruning, for example, is one of the core optimization techniques built into TensorFlow MOT.
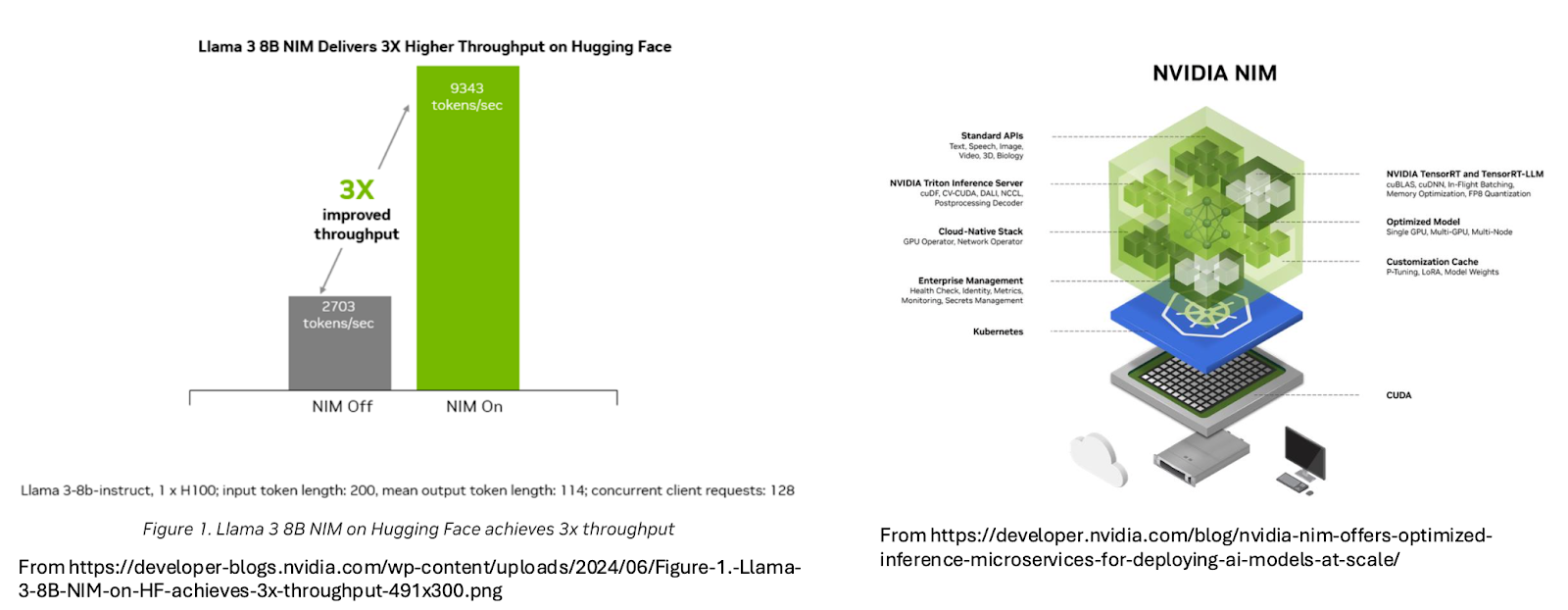
NVIDIA competitor, AMD, has been aggressively accreting software framework technology via the acquisition of companies such as Mipsology, Silo.ai and Nod.ai. All in aid of countering the significant advantages brought to NVIDIA’s hardware by its extensive software technology, including its CUDA parallel programming platform and NIM (NVIDIA Inference Microservices) framework.
In NVIDIA’s recent work published together with Hugging Face, the full impact of turning NIM on was seen in the 3x improvement in tokens/second performance. Note the functionality embedded within NIM.
Applications Architecture
Modern software applications, from lightweight mobile apps like Instagram to complex systems such as automobile operating systems, can encompass 1 million to 100 million lines of code. This underscores the necessity of integrating energy-awareness into software design from the outset, treating it as an architectural attribute alongside scalability and latency. Neglecting this early integration will otherwise result in a challenging / insuperable retrofitting process for energy-efficiency at some later point, in what will eventually become a large, legacy application.
Key architectural strategies include simplifying code through pruning layers and nodes, reducing instruction counts, training with minimal data as in SLMs, and employing techniques like RAG and p-tuning to minimize training overhead. Additionally, incorporating drift tolerance, zero-shot and transfer learning, optimizing job schedules, and carefully selecting cloud computing resources are essential practices.
Measurement
Of salient importance is also the requirement of measuring the climate impacts of AI models. Per the old saw, you can’t improve what you can’t measure. The tools for monitoring the energy footprints from AI are many, readily supplied by cloud vendors such as Amazon, Google, Microsoft and NVIDIA. As well, there are multiple third-party solutions available from the likes of Carbontracker, Cloud Carbon, PowerAPI, CodeCarbon, ML Commons and ML CO2 Impact.
Watt’s Up? Policies!
“Into the corner, broom! broom! Be gone!” from Goethe’s The Sorcerer’s Apprentice
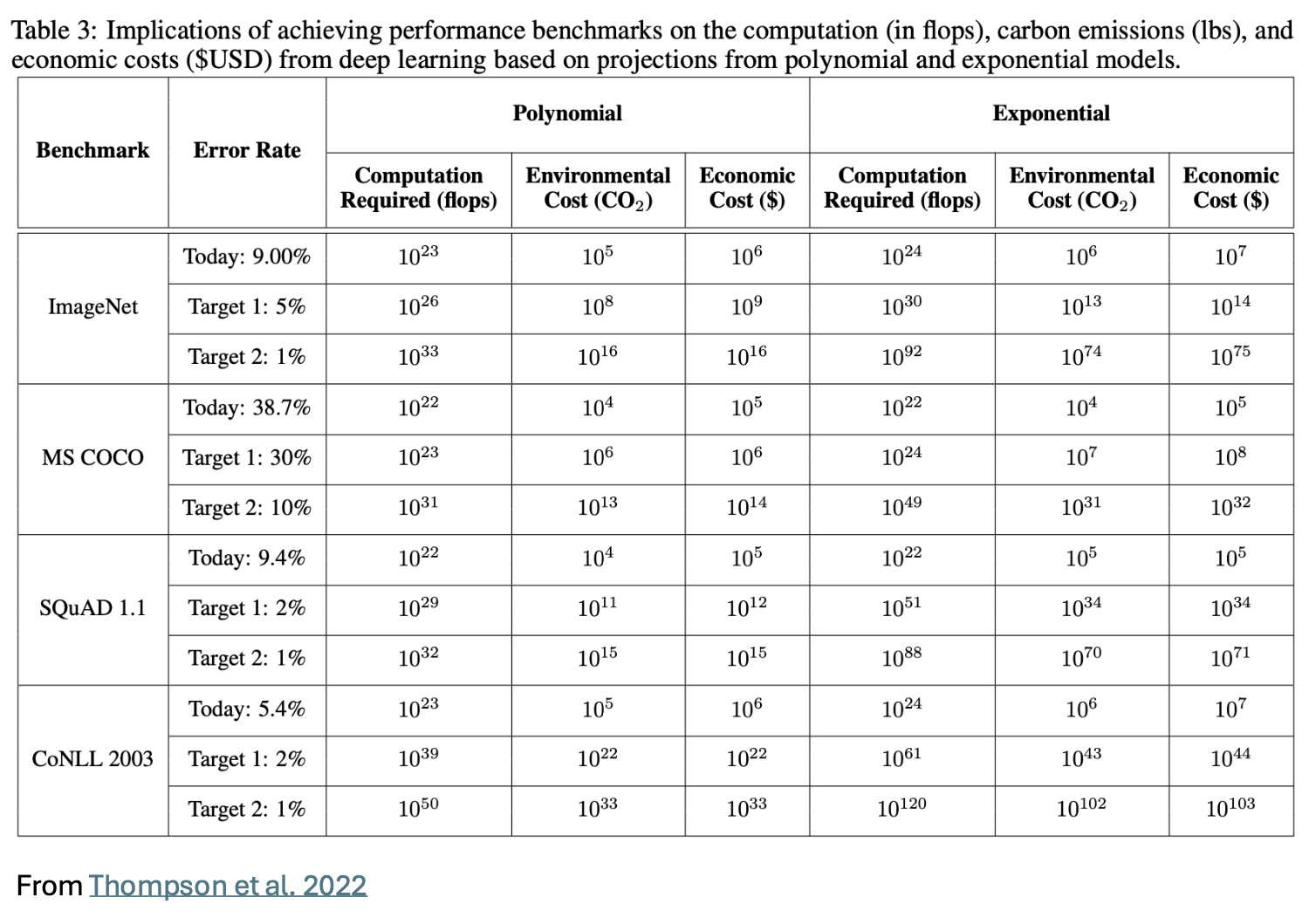
AI is becoming ever more ubiquitous, leading to ever larger demands on our straining power grid. Despite all of the measures that can be taken to dampen the power and environmental impacts of AI, such as the methods described here, AI technology is fighting a losing battle with itself. The International Energy Agency recently found that “The combination of rapidly growing size of models and computing demand are likely to outpace strong energy efficiency improvements, resulting in a net growth in total AI-related energy use in the coming years.” This conclusion mirrored one that was reached by researchers from MIT (Thompson et al. 2022), which stated “that progress across a wide variety of applications is strongly reliant on increases in computing power. Extrapolating forward this reliance reveals that progress along current lines is rapidly becoming economically, technically, and environmentally unsustainable”.
What can we do? The answer lies in governing our actions through policies at three levels: as individuals, as corporations, and as polities. Reducing AI energy demand stands as both a moral imperative and a sound business practice.
To mitigate AI’s climate impact, regulatory measures are inevitable. Following the 1973 oil crisis, the precedent set by 1975’s Corporate Average Fuel Economy (CAFE) standards, which mandated fuel efficiency for U.S. automobiles, demonstrated the effectiveness of energy regulations. Complemented by state-level gasoline taxes, these standards have continued to drive consumers towards more environmentally-friendly, fuel-efficient vehicles.
In the face of our burgeoning climate crisis we can expect similar regulations addressing carbon impacts globally. Recent examples include Denmark’s carbon emissions tax on livestock and California’s Senate Bill 253 (SB 253). The urgency of climate change necessitates robust legislative responses worldwide.
Historically, the 1973 oil crisis favored companies that had already adopted energy-efficient technologies, notably the Japanese auto industry, while the U.S. auto industry, reliant on less efficient vehicles, struggled to recover its industry dominance (Candelo 2019, Kurihara 1984). This underscores the benefits of early adoption of energy efficiency.
California’s SB 253, which requires corporations with revenues over $1 billion to disclose greenhouse gas emissions, is a positive step but could be improved. A broader reporting threshold, similar to the $25 million revenue threshold of the 2018 California Consumer Privacy Act, would be more effective. Greenhouse gases are pollutants, and given the gravity of the climate crisis, we must consider the impact of AI, including from companies with less than $1 billion in revenue.
Smaller technology companies might argue that compliance with SB 253’s reporting requirements is burdensome. However, integrating energy efficiency from the start — like the early adoption seen in Japanese automobiles prior to 1973’s oil crunch — offers competitive advantages. As climate constraints increase, energy-efficient products will be more viable, making early compliance beneficial.
Regulation akin to CAFE standards for AI is likely forthcoming in every jurisdiction worldwide. Start-ups that adopt energy-efficient practices early will be better prepared for future regulations and market demands. Additionally, energy-efficient AI products are more cost-effective to operate, enhancing their appeal to business customers and supporting long-term growth.
Corporate AI policies should prioritize employee education on climate issues to build a knowledgeable workforce capable of advancing sustainability. Product design must incorporate environmental considerations, and operational expenditure (e.g., selecting a cloud service provider) should focus on minimizing ecological impact. Accurate measurement and reporting of environmental metrics are essential for transparency and accountability. Companies should also anticipate future regulatory requirements related to climate impacts and design products to comply proactively. Finally, corporate policy requires avoiding methods that do not yield tangible carbon impact. Adopting these practices will support environmental sustainability and enhance positioning within an evolving regulatory framework.
For AI policies at the individual level, we should all remain cognizant of the environmental impacts associated with artificial intelligence. It’s important to use AI technologies judiciously, recognizing both their potential benefits and their contributions to climate change. Furthermore, sharing this awareness with others can help amplify the understanding of AI’s climate implications, fostering a broader community of informed and responsible technology users. By integrating these personal policies, individuals can contribute to a more sustainable approach to AI utilization.
In Goethe’s poem “The Sorcerer’s Apprentice”, the apprentice’s reckless use of magical powers without sufficient understanding or control leads to chaos and disaster, as “autonomous AI” brooms flood the house with water beyond the apprentice’s ability to manage. This allegory resonates with the contemporary challenges of AI automation. Just as the apprentice’s unchecked use of magic brings unforeseen consequences, so too can the unregulated deployment of AI technologies result in unintended and harmful climate outcomes. Goethe’s poem underscores the necessity of constraining and governing powerful tools to prevent them from spiraling out of control. Effective oversight and regulation are crucial in ensuring that AI, like the sorcerer’s magic, is harnessed responsibly and ethically, preventing the potential for technological advances to exacerbate existing issues or create new ones.

An Inconvenient Truth: Smoke Signals
Your cell phone has smokestack emissions. So too does your electric vehicle. The simple reason for this is that, here in the US, only 3.6% of energy supply in 2023 came from renewable sources such as wind, solar, hydroelectric and geothermal. Fossil fuels remain our predominant way of generating electricity.
The picture is equally bleak on a worldwide basis, with fossil fuels meeting the bulk of our energy demands, turning every electrically powered device, from cell phone, to electric vehicle, to data center server, into an exhaust-spewing challenge to Mother Nature.
In our increasingly digitized world, the needs from computation, and artificial intelligence in particular, are now creating a profound new climate stress. As the use of AI spreads into all aspects of human life and business, it extends ever more its demands for power and water.
Just how much power and water are we talking about? AI-driven data center power consumption is slated to soon reach 8.4 TWh (Chien 2023) which “is 3.25 gigatons of CO2, the equivalent of 5 billion U.S. cross-country flights”. Yale’s School of the Environment found that “Data centers’ electricity consumption in 2026 is projected to reach 1,000 terawatts, roughly Japan’s total consumption” (Berreby 2024), while researchers at UC Riverside found that the global AI demand for water in 2027 would be 4.2-6.6 billion cubic meters, roughly equivalent to the consumption of “half of the United Kingdom” (Li et al. 2023). Ouch.
To address the accelerating demands of AI’s energy consumption, the ideal solution would be to transition to 100% renewable energy, but this goal is currently distant. A more feasible approach is the syncretic one, combining specialized AI hardware and software, innovative data center designs, and the implementation of comprehensive AI policies, including regulation. This discussion will outline current strategies for reducing AI’s energy demands, with many solutions derived from software technology, thus enhancing their accessibility to AI practitioners.
Data Center Design
To address the heat generated by AI computations in data centers, which necessitates significant cooling energy, multiple different cooling methods can be employed. Free air cooling, which uses outdoor air to cool indoor environments, is highly efficient and uses minimal water but only works in cooler climates. Evaporative (adiabatic) cooling also provides efficient cooling with low power and water usage. Some recent designs utilize submersion cooling, where hardware is immersed in a dielectric fluid that transfers heat without conducting electricity, thus eliminating the need for traditional air conditioning. Conversely, mechanical air conditioning is least effective due to high power and water costs.
While nuclear power via small modular reactors (SMRs) is sometimes proposed as a cleaner energy solution for data centers, their deployment will take years, and they face similar safety, waste, and economic concerns as larger reactors. Instead, focusing on renewable energy sources and storage solutions, such as solar power, may offer more immediate benefits for meeting data center energy needs.
Specialized Chips
Since the mid-19th century, internal combustion engines have evolved into highly specialized devices for various applications, from lawnmowers to jumbo jets. Today, AI hardware is undergoing a similar evolution, with specialized, high-performance processors replacing less efficient general-purpose CPUs. Google’s introduction of the tensor processing unit (TPU) in 2015 marked a bellwether advance in custom-designed AI hardware. NVIDIA’s GPUs, which excel in parallel processing for deep learning and large-scale data operations, have driven substantial growth in both sales and stock valuation. As AI demand increases, we can anticipate a proliferation of vendors offering increasingly specialized processors that deliver superior computation speeds at lower energy costs.
Recent examples of this inevitable wave include Groq, a company building a language processing unit (LPU). Groq claims its custom hardware runs generative AI models similar to those from OpenAI “at 10x the speed and one-tenth the energy”. Also included in the list is Cerebras Systems’ wafer-scale chip, which “runs 20 times faster than NVIDIA GPUs”. Then there’s Etched’s Sohu ASIC, which burns the transformer architecture directly into the silicon, so “can run AI models an order of magnitude faster and cheaper than GPUs”; SiMa.ai which claims “10x performance”; and of course Amazon’s Trainium, Graviton and Inferentia processors.
The future of chip innovation may lie in biomimetic design, inspired by nature’s energy-efficient intelligence. Technologies like those developed by FinalSpark are expected to contribute to this trend. However, access to specialized processors is likely to remain a competitive landscape, with smaller companies facing particular challenges.
Orchestrating the Cooling Plant
Data center cooling equipment includes chillers, pumps and cooling towers. Can this equipment be run in an optimal fashion in order to maximize cooling while minimizing energy? In 2016, engineers at Google did just that, implementing a neural network (Evans & Gao 2016) featuring five hidden layers with 50 nodes per layer, and 19 discrete input variables, including data from the cooling equipment and weather conditions outdoors. Trained on 2 years’ worth of operating data, this neural network succeeded in reducing the energy used for cooling Google’s data centers by a whopping 40%. (Despite this, Google’s greenhouse gas emissions have skyrocketed 48% in the past 5 years thanks to the relentless demands of AI.)
Orchestrating AI Training & Inference
In addition to using software to orchestrate the cooling machinery in a data center, the same can be done with the AI applications running there. By optimizing what gets run (if at all), where it’s run and when it’s run, data centers can achieve substantial energy savings on their AI workloads. (As a simple example, imagine moving an AI workload from the afternoon to the early morning hours and saving 10% of the energy right off the bat.).
Orchestration of AI falls into two categories: orchestrating the AI training process, and orchestrating AI at inference (runtime). There are a number of different approaches being taken in the orchestration of AI training. Two promising tacks are power-capping (McDonald et al. 2022) and training performance estimation (TPE; Frey et al. 2022). In the former, standard NVIDIA utilities were used to cap the power budget available for training a BERT language model. Though the power cap led to a longer time-to-train, the resulting energy savings were material, with “a 150W bound on power utilization [leading] to an average 13.7% decrease in energy usage and 6.8% increase in training time.”
TPE is based on the principle of early stopping during AI training. Instead of training every model and hyperparameter configuration to full convergence over 100 epochs, which incurs significant energy costs, networks might be trained for only 10-20 epochs. At this stage, a snapshot is taken to compare performance with other models, allowing for the elimination of non-optimal configurations and retention of the most promising ones. “By predicting the final, converged model performance from only a few initial epochs of training, early stopping [of slow-converging models] saves energy without a significant drop in performance.” The authors note that “In this way, 80-90% energy savings are achieved simply by performing HPO [hyperparameter optimization] without training to convergence.”
Approximately 80% of AI’s workload involves inference, making its optimization crucial for energy reduction. An illustrative example is CLOVER (Li et al., 2023), which achieves energy savings through two key optimizations: GPU resource partitioning and mixed-quality models. GPU partitioning enhances efficiency by orchestrating resource utilization at the GPU level. Mixed-quality models refers to the availability of multiple models with different qualities in accuracy and resource needs. “Creating a mixture of model variants (i.e., a mixture of low- and high-quality models) provides an opportunity for significant reduction in the carbon footprint” by allowing the best model variant to be orchestrated at runtime, trading off accuracy against carbon savings. CLOVER’s mixed-quality inference services combined with GPU partitioning has proven highly effective, yielding “over 75% carbon emission savings across all applications with minimal accuracy degradation (2-4%)”.
Orchestration from a portfolio of mixed-quality models brings tremendous promise. Imagine intelligently trading off energy versus accuracy at runtime based on real-time requirements. As a further example, it’s been shown that “the answers generated by [the smaller] GPT-Neo 1.3B have similar quality of answers generated by [the larger] GPT-J 6B but GPT-Neo 1.3B only consumes 27% of the energy” and 20% as much disk (Everman et al. 2023). Yet another impactful approach to orchestration by cascading mixed-quality LLMs was shown in FrugalGPT (Chen et al. 2023). A key technique in FrugalGPT was to use a cascaded architecture to avoid querying high-resource-demand GPT-4 as long as lower-resource-demand GPT-J or J1-L were able to produce high-quality answers. “FrugalGPT can match the performance of the best individual LLM (e.g. GPT-4) with up to 98% cost reduction or improve the accuracy over GPT-4 by 4% with the same cost”.
Also notable in orchestrating machine learning inference is Kairos (Li et al. 2023). Kairos is a runtime framework that enhances machine learning inference by optimizing query throughput within quality and cost constraints. It achieves this by pooling diverse compute resources and dynamically allocating queries across that fabric for maximum efficiency. By leveraging similarities in top configurations, Kairos selects the most effective one without online evaluation. This approach can double the throughput of homogeneous solutions and outperform state-of-the-art methods by up to 70%.
From an innovation standpoint, a market opportunity exists for providing optimized AI orchestration to the data center. Evidence of the importance of AI orchestration may be seen in NVIDIA’s recent acquisition of Run:ai, a supplier of workload management and orchestration software.
Math: Less is More?
Reducing the complexity of mathematical operations is a key strategy for decreasing AI’s computational load and energy consumption. AI typically relies on 32-bit precision numbers within multi-dimensional matrices and dense neural networks. Transformer-based models like ChatGPT also use tokens in their processing. By minimizing the size and complexity of numbers, matrices, networks and tokens, significant computational savings can be achieved with minimal loss of accuracy.
Quantization, the process of reducing numerical precision, is central to this approach. It involves representing neural network parameters with lower-precision data types, such as 8-bit integers instead of 32-bit floating point numbers. This reduces memory usage and computational costs, particularly for operations like matrix multiplications (MatMul). Quantization can be applied in two ways: post-training quantization (PTQ), which rounds existing networks to lower precision, and quantization-aware training (QAT), which trains networks directly using low-precision numbers.
Recent work with OneBit (Xu et al. 2024), BitNet (QAT: Wang et al. 2023) and BiLLM (PTQ: Huang et al. 2024) have shown the efficacy – delivering accuracy while reducing memory and energy footprint – of reduced bit-width approaches. BiLLM, for example, approximated most numbers with a single bit, but utilized 2 bits for salient weights (hence average bit-widths > 1). With overall bit-widths of around 1.1, BiLLM was able to deliver consistently low perplexity scores despite its lower memory and energy costs.
Reinforcing the potential for 1-bit LLM variants is BitNet b1.58 (Ma et al. 2024), “where every parameter is ternary, taking on values of {-1, 0, 1}.” The additional value of 0 was injected into the original 1-bit BitNet, resulting in 1.58 bits in the binary system. BitNet b1.58 “requires almost no multiplication operations for matrix multiplication and can be highly optimized. Additionally, it has the same energy consumption as the original 1-bit BitNet and is much more efficient in terms of memory consumption, throughput and latency compared to FP16 LLM baselines”. BitNet b1.58 was found to “match full precision LLaMA LLM at 3B model size in terms of perplexity, while being 2.71 times faster and using 3.55 times less GPU memory. In particular, BitNet b1.58 with a 3.9B model size is 2.4 times faster, consumes 3.32 times less memory, but performs significantly better than LLaMA LLM 3B.”
Ternary neural networks (Alemdar et al. 2017) that constrain weights and activations to {−1, 0, 1} have proven to be very efficient (Liu et al. 2023, Zhu et al. 2024) because of their reduced use of memory and ability to eliminate expensive MatMul operations altogether, requiring simple addition and subtraction only. Low-bit LLMs further lend themselves to implementation in (high-performance) hardware, with native representation of each parameter as -1, 0, or 1, and simple addition or subtraction of values to avoid multiplication. Indeed, the Zhu work achieved “brain-like efficiency”, processing billion-parameter scale models at 13W of energy (lightbulb-level!), all via a custom FPGA built to exploit the lightweight mathematical operations.
Low-Rank Adaptation (LoRA; Hu et al. 2021) is a technique designed to fine-tune large pre-trained models efficiently by focusing on a low-rank (lower-dimensionality) approximation of the model’s weight matrices. Instead of updating all the model parameters, LoRA introduces additional low-rank matrices that capture essential adaptations while keeping the original weights mostly unchanged. This approach reduces computational costs and storage requirements, making it feasible to adapt large models to specific tasks with limited resources. “LoRA can reduce the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times.” In addition, LORA provides better model quality “despite having fewer trainable parameters, a higher training throughput, and, unlike adapters, no additional inference latency”.
Neural network pruning achieves computational efficiency via the technique of reducing the size of a trained neural network by removing unnecessary connections (weights) or even entire neurons, thus making the network smaller, faster, and more efficient without significantly sacrificing performance. The concept was first introduced in the paper “Optimal Brain Damage” (Le Cun et al. 1989), and has been much advanced (Han et al. 2015) in the recent past. The efficiencies reported in Han et al.’s work were substantial: “On the ImageNet dataset, our method reduced the number of parameters of AlexNet by a factor of 9×, from 61 million to 6.7 million, without incurring accuracy loss. Similar experiments with VGG-16 found that the total number of parameters can be reduced by 13×, from 138 million to 10.3 million, again with no loss of accuracy.”
Knowledge distillation is a technique for reducing neural network size by transferring generalized knowledge from a larger “teacher” model to a smaller “student” model, perhaps similar to the Hoskins Effect in virology. This process involves distilling the teacher model’s probability distributions into the student model, which results in a more compact network that maintains high performance at lower resource costs. Knowledge distillation has proven effective in tasks such as image identification (Beyer et al., 2021), pedestrian detection (Xu et al., 2024), and small language models. For instance, NVIDIA and Mistral AI’s Mistral-NeMo-Minitron 8B achieved superior accuracy compared to other models by combining neural network pruning and knowledge distillation, despite using orders of magnitude fewer tokens.
Small language models (SLMs) also offer a method to reduce computational load and energy consumption. While SLMs are often discussed in the context of on-device applications, such as those from Microsoft and Apple, they also decrease computational and energy demands in data center environments. SLMs are characterized by smaller datasets, fewer parameters, and simpler architectures. These models are designed for low-resource settings, requiring less energy for both inference and training. Research (Schick & Schütze 2020) indicates that SLMs can achieve performance comparable to GPT-3 while having orders of magnitude fewer parameters.
Another notable optimization approach is SPROUT (Li et al., 2024), which reduces transformer math and carbon impact by decreasing the number of tokens used in language generation. SPROUT’s key insight is that the carbon footprint of LLM inference depends on both model size and token count. It employs a “generation directives” (similar to compiler directives) mechanism to adjust autoregressive inference iterations, achieving over 40% carbon savings without compromising output quality.
One last method for reducing AI’s computational load that brings promise is neuro-symbolic AI (NSAI; Susskind et al. 2021). NSAI integrates neural networks with symbolic reasoning, combining the strengths of both: neural networks excel at pattern recognition from large data sets, while symbolic reasoning facilitates logic-based inference. This integration aims to overcome the energy demands of neural networks and the rigidity of symbolic systems, creating more robust and adaptable AI. Research indicates that NSAI can achieve high accuracy with as little as 10% of the training data, potentially representing a pathway to sustainable AI.
Edge Computing
It should be noted that pushing AI computation to the edge, e.g., onto your mobile device, does have the effect of reducing the 40% of data center energy that’s currently spent on cooling. Energy and carbon impacts are however still incurred from charging your mobile device.
Development Frameworks
The battle for AI chip supremacy is being fought equally on the silicon as well as on the software framework that’s built atop the silicon. These frameworks increasingly provide native support for the sorts of math optimizations that have been described in this article. Pruning, for example, is one of the core optimization techniques built into TensorFlow MOT.
NVIDIA competitor, AMD, has been aggressively accreting software framework technology via the acquisition of companies such as Mipsology, Silo.ai and Nod.ai. All in aid of countering the significant advantages brought to NVIDIA’s hardware by its extensive software technology, including its CUDA parallel programming platform and NIM (NVIDIA Inference Microservices) framework.
In NVIDIA’s recent work published together with Hugging Face, the full impact of turning NIM on was seen in the 3x improvement in tokens/second performance. Note the functionality embedded within NIM.
Applications Architecture
Modern software applications, from lightweight mobile apps like Instagram to complex systems such as automobile operating systems, can encompass 1 million to 100 million lines of code. This underscores the necessity of integrating energy-awareness into software design from the outset, treating it as an architectural attribute alongside scalability and latency. Neglecting this early integration will otherwise result in a challenging / insuperable retrofitting process for energy-efficiency at some later point, in what will eventually become a large, legacy application.
Key architectural strategies include simplifying code through pruning layers and nodes, reducing instruction counts, training with minimal data as in SLMs, and employing techniques like RAG and p-tuning to minimize training overhead. Additionally, incorporating drift tolerance, zero-shot and transfer learning, optimizing job schedules, and carefully selecting cloud computing resources are essential practices.
Measurement
Of salient importance is also the requirement of measuring the climate impacts of AI models. Per the old saw, you can’t improve what you can’t measure. The tools for monitoring the energy footprints from AI are many, readily supplied by cloud vendors such as Amazon, Google, Microsoft and NVIDIA. As well, there are multiple third-party solutions available from the likes of Carbontracker, Cloud Carbon, PowerAPI, CodeCarbon, ML Commons and ML CO2 Impact.
Watt’s Up? Policies!
“Into the corner, broom! broom! Be gone!” from Goethe’s The Sorcerer’s Apprentice
AI is becoming ever more ubiquitous, leading to ever larger demands on our straining power grid. Despite all of the measures that can be taken to dampen the power and environmental impacts of AI, such as the methods described here, AI technology is fighting a losing battle with itself. The International Energy Agency recently found that “The combination of rapidly growing size of models and computing demand are likely to outpace strong energy efficiency improvements, resulting in a net growth in total AI-related energy use in the coming years.” This conclusion mirrored one that was reached by researchers from MIT (Thompson et al. 2022), which stated “that progress across a wide variety of applications is strongly reliant on increases in computing power. Extrapolating forward this reliance reveals that progress along current lines is rapidly becoming economically, technically, and environmentally unsustainable”.
What can we do? The answer lies in governing our actions through policies at three levels: as individuals, as corporations, and as polities. Reducing AI energy demand stands as both a moral imperative and a sound business practice.
To mitigate AI’s climate impact, regulatory measures are inevitable. Following the 1973 oil crisis, the precedent set by 1975’s Corporate Average Fuel Economy (CAFE) standards, which mandated fuel efficiency for U.S. automobiles, demonstrated the effectiveness of energy regulations. Complemented by state-level gasoline taxes, these standards have continued to drive consumers towards more environmentally-friendly, fuel-efficient vehicles.
In the face of our burgeoning climate crisis we can expect similar regulations addressing carbon impacts globally. Recent examples include Denmark’s carbon emissions tax on livestock and California’s Senate Bill 253 (SB 253). The urgency of climate change necessitates robust legislative responses worldwide.
Historically, the 1973 oil crisis favored companies that had already adopted energy-efficient technologies, notably the Japanese auto industry, while the U.S. auto industry, reliant on less efficient vehicles, struggled to recover its industry dominance (Candelo 2019, Kurihara 1984). This underscores the benefits of early adoption of energy efficiency.
California’s SB 253, which requires corporations with revenues over $1 billion to disclose greenhouse gas emissions, is a positive step but could be improved. A broader reporting threshold, similar to the $25 million revenue threshold of the 2018 California Consumer Privacy Act, would be more effective. Greenhouse gases are pollutants, and given the gravity of the climate crisis, we must consider the impact of AI, including from companies with less than $1 billion in revenue.
Smaller technology companies might argue that compliance with SB 253’s reporting requirements is burdensome. However, integrating energy efficiency from the start — like the early adoption seen in Japanese automobiles prior to 1973’s oil crunch — offers competitive advantages. As climate constraints increase, energy-efficient products will be more viable, making early compliance beneficial.
Regulation akin to CAFE standards for AI is likely forthcoming in every jurisdiction worldwide. Start-ups that adopt energy-efficient practices early will be better prepared for future regulations and market demands. Additionally, energy-efficient AI products are more cost-effective to operate, enhancing their appeal to business customers and supporting long-term growth.
Corporate AI policies should prioritize employee education on climate issues to build a knowledgeable workforce capable of advancing sustainability. Product design must incorporate environmental considerations, and operational expenditure (e.g., selecting a cloud service provider) should focus on minimizing ecological impact. Accurate measurement and reporting of environmental metrics are essential for transparency and accountability. Companies should also anticipate future regulatory requirements related to climate impacts and design products to comply proactively. Finally, corporate policy requires avoiding methods that do not yield tangible carbon impact. Adopting these practices will support environmental sustainability and enhance positioning within an evolving regulatory framework.
For AI policies at the individual level, we should all remain cognizant of the environmental impacts associated with artificial intelligence. It’s important to use AI technologies judiciously, recognizing both their potential benefits and their contributions to climate change. Furthermore, sharing this awareness with others can help amplify the understanding of AI’s climate implications, fostering a broader community of informed and responsible technology users. By integrating these personal policies, individuals can contribute to a more sustainable approach to AI utilization.
In Goethe’s poem “The Sorcerer’s Apprentice”, the apprentice’s reckless use of magical powers without sufficient understanding or control leads to chaos and disaster, as “autonomous AI” brooms flood the house with water beyond the apprentice’s ability to manage. This allegory resonates with the contemporary challenges of AI automation. Just as the apprentice’s unchecked use of magic brings unforeseen consequences, so too can the unregulated deployment of AI technologies result in unintended and harmful climate outcomes. Goethe’s poem underscores the necessity of constraining and governing powerful tools to prevent them from spiraling out of control. Effective oversight and regulation are crucial in ensuring that AI, like the sorcerer’s magic, is harnessed responsibly and ethically, preventing the potential for technological advances to exacerbate existing issues or create new ones.