")
Why Hallucinations Matter: Misinformation, Brand Safety and Cybersecurity in the Age ofGenerative AI

“There are three kinds of lies: lies, damned lies, and statistics.” – Mark Twain (maybe)
AI Generates Pink Elephant
In the present day, Mark Twain’s (or Benjamin Disraeli’s?) supposed quote might better be recast as, “There are three kinds of lies: lies, damned lies, and hallucinations”. In our age of generative AI, the technology’s propensity to create false, unrelated, “hallucinated” content may be its greatest weakness. Major brands have repeatedly fallen victim to hallucination or adversarial prompting, resulting in both lost brand value and lost company value. Notable examples include the chatbot for the delivery firm, DPD, aspersing the company; Air Canada having been found financially liable by the Canadian courts for real-time statements made by its chatbot; inappropriate image generation issues at Midjourney and Microsoft; and of course, Google losing $100 billion in market value in a single day following a factual error made by its Bard chatbot. In each instance, brand value that was carefully accreted in the age of static content did not prove resilient to hallucination from the age of generative AI content.
Hallucinations in AI are vitally important, particularly as we enter a world where AI-enabled agents become ubiquitous in our personal and professional lives. Humans communicate principally via language, through both sight and sound, and our latest AI breakthroughs in large language models (LLMs) portend a quantum jump in how we’ll evermore communicate with our computers. Brain-computer interfaces notwithstanding, conversational language with agents will be our ultimate interface to AI as collaborator. In such a scenario, with trust paramount, we cannot afford the risk of hallucinated AI output. But hallucinations and our agent-based future are now firmly on a collision course.
In addition, in days gone by, a devious hacker might have targeted corporate information systems through deep knowledge of programming languages, SQL, and the attack surfaces within technology stacks. Today, thanks to the ubiquity of natural language interfaces to the fabric of computing, a devious hacker can attack a brand by being proficient in just a single area of technology: the ability to communicate via natural language.
So, what’s a brand owner to do as these risks continue to multiply? Companies such as Microsoft and Blackbird AI have started to address some of the challenges in generated content, but as an industry we’ve just begun to scratch the surface. Happily, there are a range of technologies being developed to help reduce hallucination and increase factuality. It’s imperative that all of us have a solid grasp of these solutions and the underlying problems they address. The downside risks in AI hallucination are profound and equally impact individuals, businesses and society.
Why Does Generative AI Hallucinate?
We’ve been writing computer software for 80 years and we still produce bugs in our source code, leading to execution errors. It should come as no surprise to us that, as we find ourselves engulfed by data-driven technologies such as AI, we can find “bugs” within data’s complexity and volume, leading to AI hallucinations. The etiology of AI hallucination includes biased training data, the computational complexity inherent in deep neural networks, lack of contextual / domain understanding, adversarial attack, training on synthetic data (“model collapse”), and a failure to generalize the training data (“overfitting”).
The simple model for classifying hallucinations is that they’re either of the factuality variety or of the faithfulness variety (Huang et al. 2023). As defined in Huang at al.’s survey article, “Factuality hallucination emphasizes the discrepancy between generated content and verifiable real-world facts, typically manifesting as factual inconsistency or fabrication”, while “faithfulness hallucination refers to the divergence of generated content from user instructions or the context provided by the input, as well as self-consistency within generated content”. More simply, factual hallucinations get output facts wrong, while faithfulness hallucinations are unexpected (bizarre) outputs.
AI’s Anti-hallucinogens
Addressing the causes of AI hallucination or inaccuracy has typically involved improving the quality of prompts as well as better tuning the LLM model. Too, there are emerging techniques for scoring LLM outputs for factuality. The number of technologies being developed across these categories to capture factuality and faithfulness is large and increasing. A taxonomy pipeline for the different types of mitigations might be as follows:
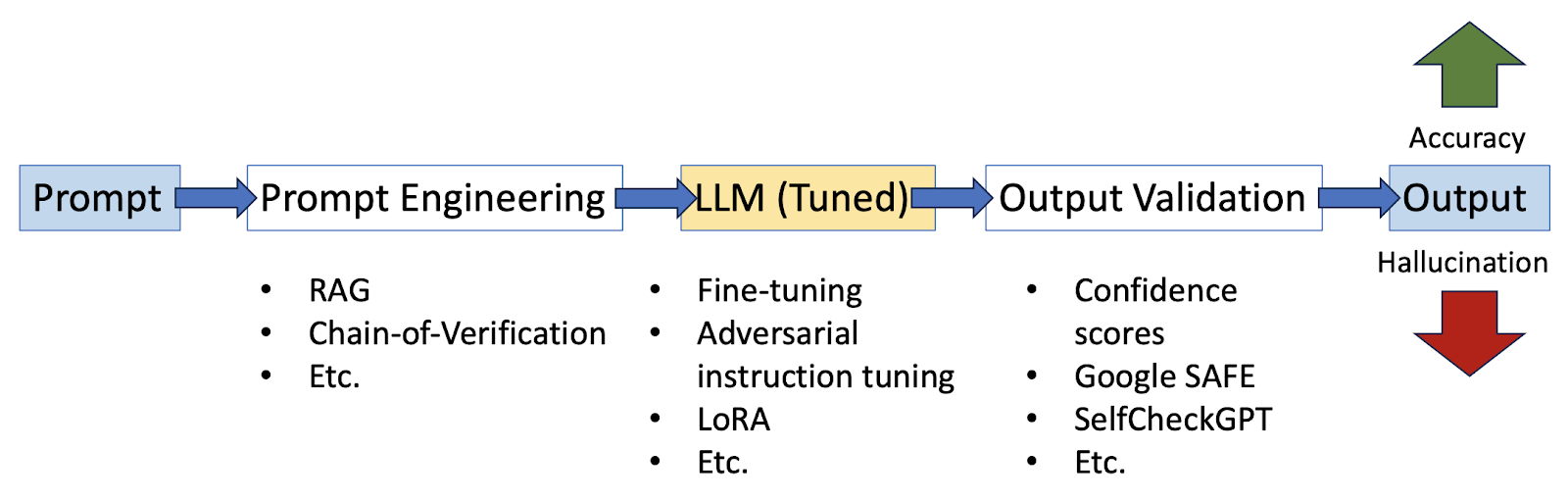
Before we discuss threats to brand safety and cybersecurity, let’s take a look at a few of the more prominent AI anti-hallucinogens. This list is not definitive and is meant merely to give a flavoring for the types of solutions now available. Brand owners today, as much as technologists, will need a familiarity with all current approaches.
Prompt Engineering
Prompt engineering involves crafting specific prompts or instructions that guide the LLM towards generating more factual and relevant text. Providing additional context or examples within the prompt can significantly reduce hallucinations.
Prompt engineering may be our most accessible means of hallucination mitigation, but the familiar manual approach is neither scalable nor optimal. The future of prompt engineering is programmatic. LLMs are models, after all, and models are best manipulated not by human intuition but by bot-on-bot warfare featuring coldly calculating algorithms that score and self-optimize their prompts. Notable work in automated prompt engineering has been done in Google DeepMind’s OPRO (Yang et al. 2023), the aptly named Automated Prompt Engineer (APE; Zhou et al. 2023), DSPy (Khattab et al. 2023), VMware’s automatic prompt optimizer (Battle & Gollapudi 2024), and Intel’s NeuroPrompts (Rosenman et al. 2023).
Retrieval-Augmented Generation (RAG)
Retrieval-augmented generation (Lewis et al. 2020) has been a tremendous tool supporting the injection of context, in real-time, into LLM prompts, thereby improving the fidelity of generated output and the reduction of hallucination (Shuster et al. 2021).
RAG works by augmenting prompts with information retrieved from a knowledge store, for example a vector database. In the diagram below, the elements of a prompt are mapped into a vector embedding. That vector embedding is then used to find up-to-date content – indexed via a vector embedding also – that is most similar to what’s being asked for in the prompt. This additional context augments the original prompt, which is then fed into the LLM, producing a fully-contextualized response.
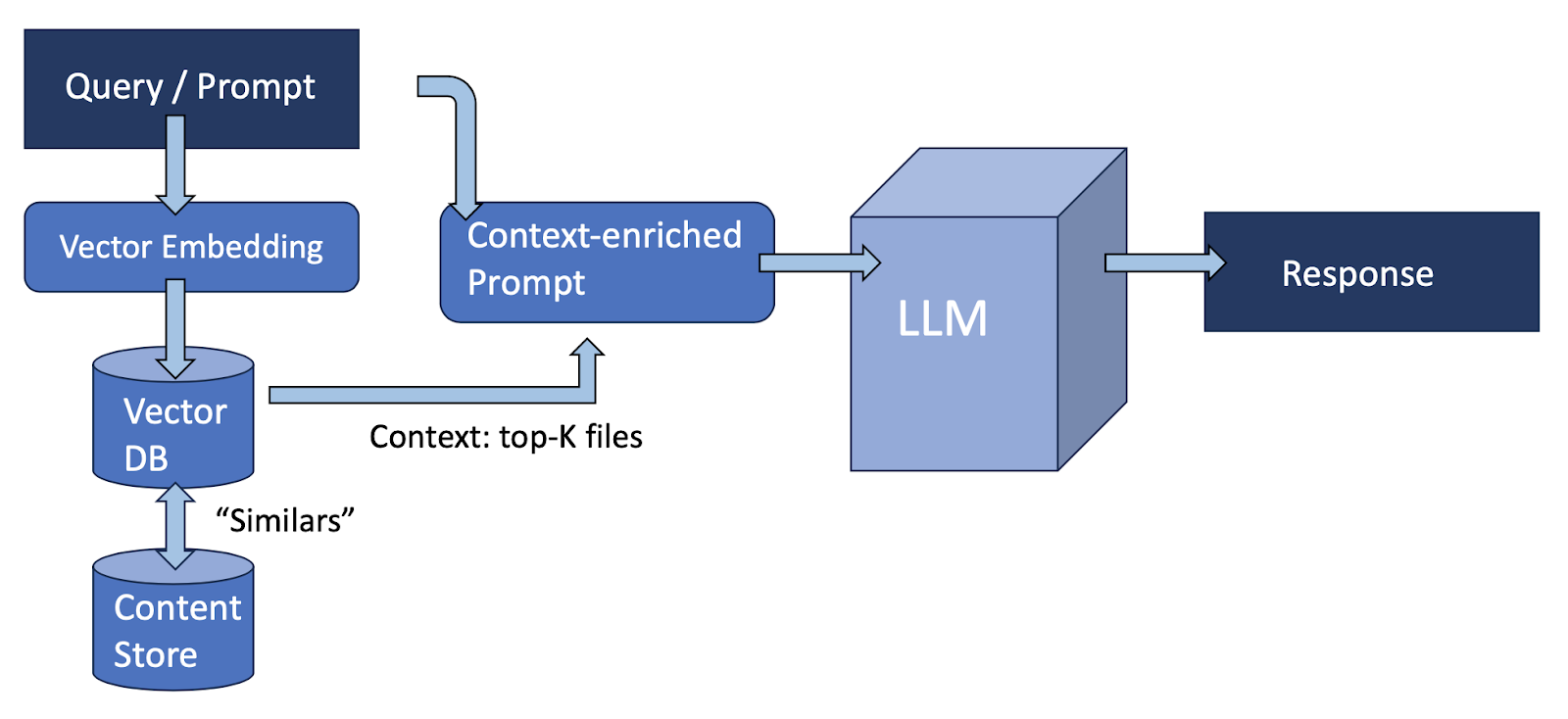
RAG has shown itself to be a powerful tool. It’s not dependent on the LLM’s internal training-time parameters, but instead boosts the original prompt with context retrieved in real-time from a knowledge store. Because no LLM retraining is required, RAG is a more resource-efficient solution than traditional fine-tuning. A poster-child application of RAG in a consumer setting was provided by BMW at the recent CES.
Fine-tuning
Fine-tuning an LLM on specific datasets focused on factual tasks (Tian et al. 2023) can significantly improve its ability to distinguish real information from fabricated content. LLM fine-tuning is the process of adapting a pre-trained language model to perform a specific task or align within a specific domain. It involves training the model on a task-specific, labeled data set, and adjusting its parameters to optimize performance for the targeted task. Fine-tuning allows a model to learn domain-specific patterns and nuances, enhancing its ability to generate relevant and accurate outputs.
Fine-tuning has its limitations, however. Its effectiveness depends on the quality and representativeness of its training data and the selection of its hyperparameters during the fine-tuning process. As fine-tuning is done prior to runtime, it also suffers from lack of access to up-to-date information (in contrast to RAG, for example). Finally, fine-tuning is computationally expensive and, depending on the complexity of the task, may bring with it a need for a significant amount of additional data.
Low-Rank Adaptation (LoRA)
Low-Rank Adaptation (Hu et al. 2021) is a technique for fine-tuning LLMs that focuses on efficiency and reducing unrealistic outputs. It works by introducing low-rank matrices, which are essentially minimized versions of the original data, into the model. This significantly reduces the number of parameters the model needs to learn, making training faster and requiring less memory.
While LoRA doesn’t directly address the root cause of hallucinations in LLMs, which stem from the biases and inconsistencies in training data, it indirectly helps by enabling more targeted fine-tuning. By requiring fewer parameters, LoRA allows for more efficient training on specific tasks, leading to outputs that are more grounded in factual information and less prone to hallucinations. This synergy between efficiency and adaptation makes LoRA an effective tool in producing high-fidelity LLM output.
Confidence Scores
Some hallucination mitigation techniques assign confidence scores to the LLM’s outputs (Varshney et al. 2023). These scores indicate how certain the model is about its generated text. It’s then possible to bowdlerize outputs in favor of high confidence scores, reducing the likelihood of encountering hallucinations. Notable work has been done here in SelfCheckGPT (Manakul et al. 2023). SelfCheckGPT detects hallucinations via sampling for factual consistency. If an LLM generates similar responses when sampled multiple times, its response is likely factual. Though the model is shown to perform well, the practicality of performing real-time consistency checks across multiple samples, in a scalable fashion, may be limited.
Yet another approach to factuality was provided via Google’s Search-Augmented Factuality Evaluator (SAFE; Wei et al. 2024). In a sort of reverse-RAG, “SAFE utilizes an LLM to break down a long-form response into a set of individual facts and to evaluate the accuracy of each fact using a multi-step reasoning process comprising sending search queries to Google Search and determining whether a fact is supported by the search results”.
Knowledge Graphs
Knowledge graphs can act as anchors for LLMs, reducing the risk of hallucination by providing a foundation of factual information. Knowledge graphs are structured databases that explicitly encode real-world entities and relationships, and connecting knowledge graphs to LLMs can provide factual utility at all stages of the generative pipeline: from providing context into prompts, during training / fine-tuning, and also in testing for factual accuracy of the prompt’s response (Guan et al. 2023). This helps ground the LLM’s responses in reality, making it less prone to hallucinations.
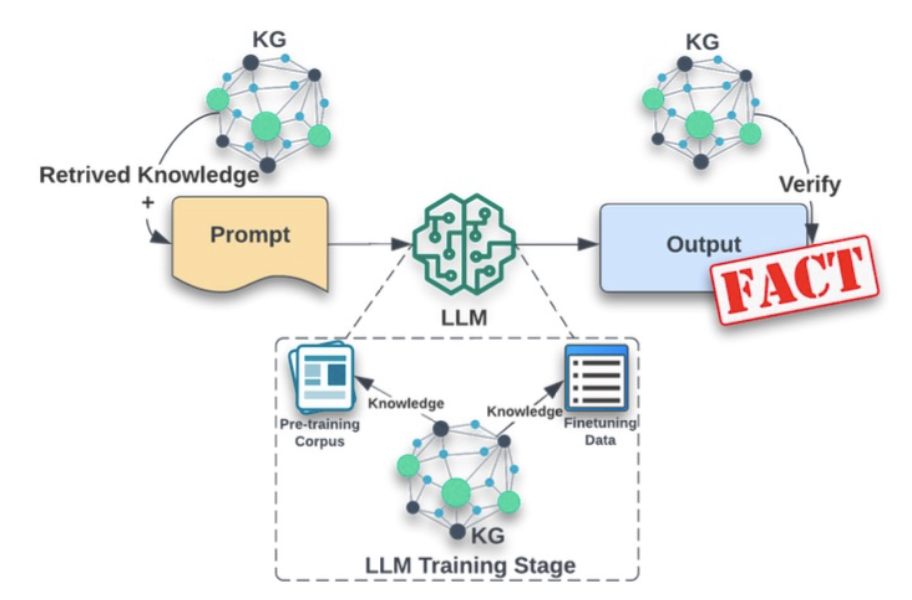
Knowledge graphs (KG) employed to reduce hallucinations in LLMs at different stages. From Agrawal et al. 2023
It’s key to note that knowledge graphs encode both facts and context. Entities within the knowledge graph are linked to each other, showing relationships and dependencies. This allows the LLM to understand how different concepts interact. When generating text, the LLM can then draw on this contextual information to ensure consistency and avoid nonsensical outputs. For example, if an LLM is prompted about an historical event, it can utilize the knowledge graph to ensure that output regarding people, places, dates and events conform with historical fact.
Garbage In, Garbage Out
“It is the habit of mankind to entrust to careless hope what they long for, and to use sovereign reason to thrust aside what they do not desire.”
Thucydides
Hallucination is inevitable. So says the title of a recent paper (Xu et al. 2024), with the researchers finding that “it is impossible to eliminate hallucination in LLMs”, specifically because “LLMs cannot learn all of the computable functions and will therefore always hallucinate”. Though we might be able to reduce the rate of hallucination through innovation, evidence shows that we will never be able to eliminate it.
Further, and dismayingly, AI’s anti-hallucinogens prove to be not just a cure for fallacy but also a steroid to enhance it. The very same techniques we might use to reduce hallucination – RAG, fine-tuning, knowledge graphs – are dependent on data, data that can easily be biased to reinforce specific views; one person’s truth is after all another’s hallucination. Simply, injecting context for “truth” in an LLM requires (the ever elusive) 100% objective data.
This brings us back to Thucydides’ quote of 2400 years ago, and history’s first recorded observation of the insuperable (and, apparently, eternal) human condition of confirmation bias. Human beings have always been particularly vulnerable to holding their own beliefs, seeking out confirmations of those beliefs, and disregarding all others. In our technology campaign for ridding generative AI of hallucinations, we’ve created tools that will help in doing just that and will equally enable the practitioners of disinformation: garbage in (toxic content in knowledge graphs, content databases, or fine-tuning), garbage out (in generative AI). As we solve one problem, we inadvertently feed another.
Recent work by Anthropic (Durmus et al. 2024) and elsewhere (Salvi et al. 2024) has produced somewhat dispiriting results, from a societal perspective, on the persuasiveness of language models, once again highlighting the critical need for AI’s factuality and faithfulness in an agent-based world. Anthropic’s work on the LLM-driven persuasion of humans found “a clear scaling trend across [AI] model generations: each successive model generation is rated to be more persuasive than the previous” and also “that our latest and most capable model, Claude 3 Opus, produces arguments that don’t statistically differ in their persuasiveness compared to arguments written by humans” (emphasis added).
The Salvi work on LLM persuasiveness went a step further, testing the impact of giving the LLM access to basic sociodemographic information about their human opponent in the persuasion exercise. The study found “that participants who debated GPT-4 with access to their personal information had 81.7% (p < 0.01; N=820 unique participants) higher odds of increased agreement with their opponents compared to participants who debated humans.” The study’s authors concluded that “concerns around personalization are meaningful and have important implications for the governance of social media and the design of new online environments”. We can absolutely anticipate that malevolent actors will use the LLM technologies now at hand to instrument conversational agent responses with all manner of multi-modal sociodemographic data in order to maximize subjective persuasion.
Agents + Hallucination = Titanic + Iceberg
“You won’t have to use different apps for different tasks. You’ll simply tell your device, in everyday language, what you want to do. … This type of software—something that responds to natural language and can accomplish many different tasks based on its knowledge of the user—is called an agent. … Agents are not only going to change how everyone interacts with computers. They’re also going to upend the software industry, bringing about the biggest revolution in computing since we went from typing commands to tapping on icons.” – Bill Gates, 2023
As Bill Gates, NVIDIA and others have rightly noted, we’re now passing into a new age of computation, one based on agents driven by conversational input/output and AI. If unified chatbot agents become our principal means of interfacing with computers, and if those agents (aka. “super-spreaders”?) are subject to all of the vulnerabilities of LLM-based generative AI – hallucination, misinformation, adversarial attack (Cohen et al. 2024), bias (Haim et al. 2024, Hofmann et al. 2024, Durmus et al. 2023) – then we’ll all suffer individually, and also collectively as businesses and societies.
Just as LLMs have shown themselves responsive to automated prompt engineering to yield desired results, so too have they shown themselves susceptible to adversarial attack via prompt engineering to yield malicious results (Yao et al. 2023, Deng et al. 2023, Jiang et al. 2024, Anil et al. 2024, Wei et al. 2023, Rao et al. 2024). Exemplary work in using an automated framework to jail-break text-to-image gen-AI, resulting in the production of not-suitable-for-work (NSFW) images, was done in the SneakyPrompt project (Yang et al. 2023). “Given a prompt that is blocked by a safety filter, SneakyPrompt repeatedly queries the text-to-image generative model and strategically perturbs tokens in the prompt based on [reinforcement learning and] the query results to bypass the safety filter.”
Beyond chatbots, the risks of hallucination extend into many other application areas of AI. LLMs have slipped into the technologies utilized to build autonomous robots (Zeng et al. 2023, Wang et al. 2024) and vehicles (Wen et al. 2024). Hallucinations have also shown themselves to be a significant issue in the field of healthcare, both in LLM-driven applications (Busch et al. 2024, Ahmad et al. 2023, Bruno et al. 2023) and in medical imaging (Bhadra 2021). Data as attack vector has been shown in self-driving vehicle technology, through “poltergeist” (Ji et al. 2021) and “phantom” (Nassi et al. 2020) attacks, and has also been demonstrated in inaudible voice command “dolphin” attacks (Zhang et al. 2017).
More unsettling still is LLM-based agents being “integrated into high-stakes military and diplomatic decision making”, as highlighted by Stanford’s center for Human-Centered Artificial Intelligence (Rivera et al. 2024). Here, the researchers found “that LLMs exhibit difficult-do-predict, escalatory behavior, which underscores the importance of understanding when, how, and why LLMs may fail in these high-stakes contexts”. In such settings, the risk hallucination may bring in escalating human conflict is clearly an unacceptable one.
From Hallucinations to “Aligned Intelligence”
Language is the human species’ chief means of communication and is conveyed via both sight and sound. The impact of LLM AI technology will remain powerful specifically because it maps so effectively the language foundation of human communication. Humans also sense and perceive the non-language parts of our world, and we do this overwhelmingly through our sense of vision. A burgeoning field within AI is consequently – and unsurprisingly – the large vision model (LVM). Are LVMs also susceptible to hallucination, like their LLM brethren? Yes.
Similar to training LLMs on massive language data sets, large vision models are trained on massive image data sets, yielding an ability for computer vision systems to understand the content and semantics of image data. As vision-based AI systems become increasingly ubiquitous in applications such as autonomous driving (Wen et al. 2023), the same issues we see in LLMs of hallucination and inaccurate results will appear in LVMs. LVMs are also responsive to prompt engineering (Wang et al. 2023), and also susceptible to hallucination (Liu et al. 2024, Li et al. 2023, Wang et al. 2024, Gunjal et al. 2023). The difference between a hallucinating LLM and hallucinating LVM may be that the latter has a better chance of actually killing you.
Finally, our current efforts to ensure alignment (Ji et al. 2023) by AI-driven agents with humans’ goals (in LLMs, for factuality and faithfulness) is part of a much broader narrative. AI continues to evolve in the direction of long-term planning agents (LTPAs). That is, autonomous AI agents that are able to go beyond mere transformer-driven token generation to instead plan and execute complex actions across very long time horizons. The nuanced, longitudinal nature of LTPAs will make it exceedingly difficult to map the faithfulness / alignment of such models, exposing humans (and the planet) to unmapped future risks.
It is for this reason that the recent article “Regulating advanced artificial agents” by Yoshua Bengio, Stuart Russell and others (Science: Cohen et al. 2024) warned that “securing the ongoing receipt of maximal rewards with very high probability would require the agent to achieve extensive control over its environment, which could have catastrophic consequences”. The authors conclude, “Developers should not be permitted to build sufficiently capable LTPAs, and the resources required to build them should be subject to stringent controls”. We might view our current efforts to contain hallucination in LLM-driven agents as merely the first crucial skirmish in what will be a far more difficult struggle in our “loss of control” with LTPAs.
Where Do We Go from Here?
“Picture living in a world where deepfakes are indistinguishable from reality, where synthetic identities orchestrate malicious campaigns, and where targeted misinformation or scams are crafted with unparalleled precision”
Ferrara 2024
Gen-AI is still in its nascence, but the damage that can accrue from the technology’s hallucination and inaccuracy is already manifold: it impacts us as individuals, it impacts AI-based systems and the companies and brands that rely on them, it impacts nations and societies. And as modern LLM-driven agents become increasingly prevalent in all aspects of daily life, the issue of hallucination and inaccuracy becomes ever more crucial.
Hallucination will remain important as long as humans communicate using words. From brand safety, to cybersecurity, to next-gen personal agents and LTPAs, factuality and faithfulness is everyone’s problem. Inadequately addressed, we risk building a generation’s worth of technology atop a foundation that is deeply vulnerable. Inevitably, we might find ourselves in a forever war, with weaponized AI agents – “AI-based psychological manipulation at internet scales within the information domain” (Feldman et al. 2024) – competing with innovation in the mitigation of hallucination and amplified misinformation. This conflict will be continuous and will forever require from us more robust and interpretable AI models, a diversity of training data, and safeguards against adversarial attack. Brand safety, system safety and most importantly, individual and societal safety, all hang in the balance.
We may now be finding that the AI “ghost in the machine” that we all should fear is not sentience, but simple hallucination. As Sophocles almost said, “Whom the gods would destroy, they first make hallucinate”.